The SS3 Classification Model
The SS3 text classifier is a novel supervised machine learning model for text classification which has the ability to naturally explain its rationale. It was originally introduced in Section 3 of the paper “A text classification framework for simple and effective early depression detection over social media streams” (preprint available here). Given its white-box nature, it allows researchers and practitioners to deploy explainable, and therefore more reliable, models for text classification (which could be especially useful for those working with classification problems by which people’s lives could be somehow affected).
Note
PySS3 also incorporates different variations of the original model, such as the one introduced in “t-SS3: a text classifier with dynamic n-grams for early risk detection over text streams” (preprint available here) which allows SS3 to recognize important variable-length word n-grams “on the fly”.
Introduction
As it is described in more detail in original paper, SS3 first builds a dictionary of words for each category during the training phase, in which the frequency of each word is stored.
Then, using these word frequencies, and during the classification stage, it calculates a value for each word using a function 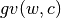 to value words in relation to each category (
to value words in relation to each category (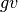 stands for “global value” of a word). takes a word
stands for “global value” of a word). takes a word 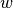 and a category
and a category  and outputs a number in the interval [0,1] representing the degree of confidence with which is believed to exclusively belong to . For instance, suppose the categories are
and outputs a number in the interval [0,1] representing the degree of confidence with which is believed to exclusively belong to . For instance, suppose the categories are 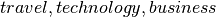 , and
, and 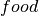 . After training, SS3 would learn to value words like “apple” and “the” as follows:
. After training, SS3 would learn to value words like “apple” and “the” as follows:
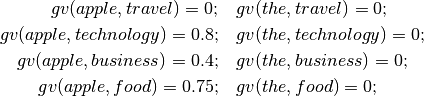
Additionally,  is the vectorial version of . is only applied to a word and it outputs a vector in which each component is the word’s for each category. For instance, following the above example, we have:
is the vectorial version of . is only applied to a word and it outputs a vector in which each component is the word’s for each category. For instance, following the above example, we have:
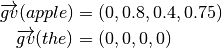
These vectors are called confidence vectors (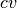 ). Thus, in this example
). Thus, in this example 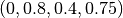 is the confidence vector of the word “apple”, in which the first position corresponds to “travel”, the second to “technology”, and so on.
is the confidence vector of the word “apple”, in which the first position corresponds to “travel”, the second to “technology”, and so on.
Classification
As it is illustrated in the Figure below, the classification algorithm can be thought of as a 2-phase process.
In the first phase, the input is split into multiple blocks (e.g. paragraphs), then each block is in turn repeatedly divided into smaller units (e.g. sentences, words). Thus, the previously “flat” document is transformed into a hierarchy of blocks.
In the second phase, the function is applied to each word to obtain the “level-0” confidence vectors, which then are reduced to “level-1” confidence vectors by means of a level-0 summary operator, 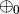 .
This reduction process is recursively propagated up to higher-level blocks, using higher-level summary operators,
.
This reduction process is recursively propagated up to higher-level blocks, using higher-level summary operators, 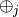 , until a single confidence vector,
, until a single confidence vector, 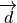 , is generated for the whole input.
Finally, the actual classification is performed based on the values of this single confidence vector, , using some policy —for example, selecting the category with the highest confidence value.
, is generated for the whole input.
Finally, the actual classification is performed based on the values of this single confidence vector, , using some policy —for example, selecting the category with the highest confidence value.
Note
By default, PySS3’s summary operators are vector additions. However, in case you want to define your own custom summary operators, the SS3 class exposes them using the following methods: SS3.summary_op_ngrams (), SS3.summary_op_sentences ( ), and SS3.summary_op_paragraphs (
), and SS3.summary_op_paragraphs ( ).
).
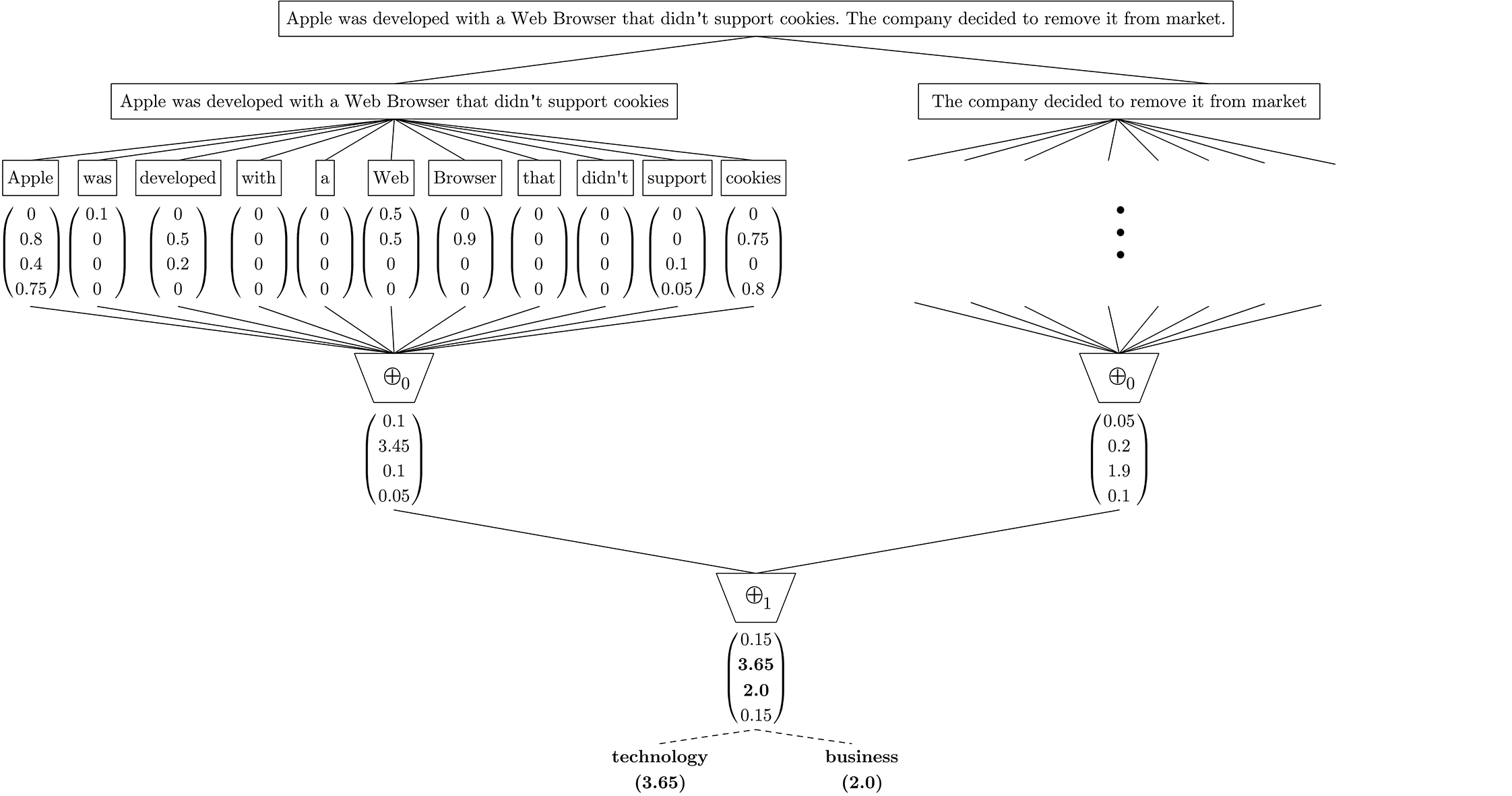
Figure: Classification process for an example document.
In the first stage, this document is split into two sentences (for instance, by using the dot as a delimiter) and then each sentence is also split into single words.
In the second stage, is computed for every word to generate the first set of confidence vectors.
Then all of these word vectors are reduced by a operator to sentence vectors, 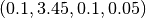 and
and 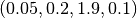 for the first and second sentence respectively.
After that, these two sentence vectors are also reduced by another operator (, which in this case is the addition operator) to a single confidence vector for the entire document,
for the first and second sentence respectively.
After that, these two sentence vectors are also reduced by another operator (, which in this case is the addition operator) to a single confidence vector for the entire document, 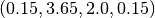 .
Finally, a policy is applied to this vector to make the classification —which in this example was to select technology, the category with the highest value, and also business because its value is “close enough” to technology’s
.
Finally, a policy is applied to this vector to make the classification —which in this example was to select technology, the category with the highest value, and also business because its value is “close enough” to technology’s
Note that using the confidence vectors in this hierarchy of blocks, it is quite straightforward for SS3 to visually justify the classification if different blocks of the input are colored in relation to their values.
Note
This characteristic is exploited by the PySS3’s Live Test tool to create the interactive visualizations. This tool can be used to monitor and analyze what the model is actually learning. You can check out the online live test demos available here (both were created following the tutorials).
Additionally, the classification is also incremental as long as the summary operator for the highest level block (, for this example) can be computed incrementally —which is the case for most common aggregation operations such as addition, multiplication, maximum, etc.
For instance, suppose that later on, a new sentence is appended to the example shown above.
Since is the addition of all vectors, instead of processing the whole document again, we could update the already computed vector, , by adding the new sentence confidence vector to it —
Note that this incremental classification, in which only the new sentence needs to be processed, would produce exactly the same result as if the process were applied to the whole document again, each time.
Hyperparameters
As it was described in the previous section, the global value () of a word is used to create the first confidence vectors, upon which higher level confidence vectors are then created until a single confidence vector for the whole input is obtained. Therefore, the global value (gv) of a word is the basic building block for the entire classification process.
In simple terms, the calculation of the global value () of a word in a category is obtained by multiplying three values. Namely, its local value, its significance factor, and its sanction factor. Additionally, in practice, the calculation of each one of these three values is controlled by a special hyperparameter. In more detail, we have:
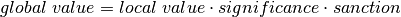
where:
The local value values the word based on its local frequency in the category.
The
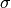 or “smoothness” hyperparameter allows you to “smooth” the relationship between the raw frequency and the final value assigned to the word. For instance,
or “smoothness” hyperparameter allows you to “smooth” the relationship between the raw frequency and the final value assigned to the word. For instance, 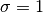 indicates the local value is calculated directly proportional to the raw frequency, whereas smaller values decrease the influence of this frequency (i.e the gap between the most and less frequent words becomes smaller). Think of this hyperparameter as if it were a “frequency tuner” that you can use to remove the “overshadowing” effect that extremely frequent words (but not important such as “the”, “on”, “with”, etc.) produce on less frequent but really useful words.
indicates the local value is calculated directly proportional to the raw frequency, whereas smaller values decrease the influence of this frequency (i.e the gap between the most and less frequent words becomes smaller). Think of this hyperparameter as if it were a “frequency tuner” that you can use to remove the “overshadowing” effect that extremely frequent words (but not important such as “the”, “on”, “with”, etc.) produce on less frequent but really useful words.
The significance factor captures the global significance of the word by decreasing the global value in relation to its local value in the other categories.
The
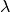 or “significance” hyperparameter allows you to controls how far the local value in a category must deviate from the local value in the other categories for the word to be considered important to that category.
or “significance” hyperparameter allows you to controls how far the local value in a category must deviate from the local value in the other categories for the word to be considered important to that category.
The sanction factor decreases the global value in relation to the number of categories the word is significant to (given by the significance value).
The
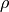 or “sanction” hyperparameter allows you to control how sensitive/severe this sanction is.
or “sanction” hyperparameter allows you to control how sensitive/severe this sanction is.
The name “SS3” is based on these three hyperparameters: Sequential Smoothness-Significance-and-Sanction (SS3).
Note
In PySS3, these hyperparameters are referenced using the “s”, “l”, and “p” letters for , , and , respectively. For instance, let’s say we want to create a new SS3 model with 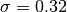 ,
, 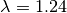 , and
, and 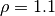 , then we can create a new
, then we can create a new SS3 object as follows:
clf = SS3(s=0.32, l=1.24, p=1.1)
Additionally, PySS3 provides a “forth hyperparameter”, called 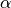 (and referenced using the “a” letter), which allows you to set the minimum global value that a word must have in order not to be ignored. That is, only words with
(and referenced using the “a” letter), which allows you to set the minimum global value that a word must have in order not to be ignored. That is, only words with 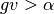 will be taken into account during classification. By default
will be taken into account during classification. By default 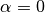 , so no word is ignored. However, let’s say we want to create the same previous SS3 model but this time using
, so no word is ignored. However, let’s say we want to create the same previous SS3 model but this time using 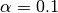 , then we could use:
, then we could use:
clf = SS3(s=0.32, l=1.24, p=1.1, a=0.1)
Tip: when working on early classification tasks, using values greater than 0 can yield better classification results.
See also
If you want to know how exactly these values are calculated in practice, as well as the formal definition of the algorithms, read Section 3 of the original paper that, along with the corresponding equations, presents the main ideas that lead to them.